NLP文本增强方法介绍
深度学习发展到如今,模型越来越庞大,参数也越来越多,尤其在NLP领域,上亿参数量的模型屡见不鲜,比如BERT、GPT、T5等,虽然有很多大厂和研究院所预训练好的各种模型开源出来供大家使用,但是在具体的任务场景中,由于领域的不同,仍需要训练或者微调这些模型。
作为有监督学习,训练数据必不可少,并且数据的质量和数量直接决定模型的上限,但是由于使用场景可能是专有领域场景,没有合用的开源数据集可以直接使用,此时就需要构建自己的数据集。构建一个数据集,最大的困难就是数据标注,因为高质量数据标注需要人工逐条标注,若要构建一个巨大的数据集,时间成本和经济成本都非常高,往往只有大厂才有实力做到,因此,在有限条件下,大量的标注数据是很难获得的,我们往往只能得到一个质量较高但数量较少的数据集。而小样本情况下模型无法达到预期效果,文本增强正是缓解这种情况的有效手段。
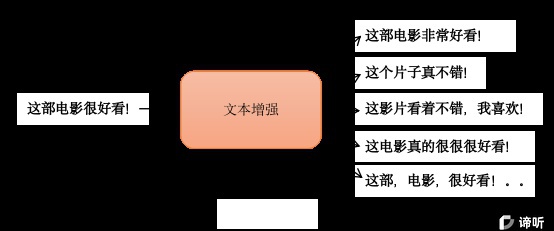
文本增强是数据增强(Data Augmentation, DA)的一种,主要用来缓解深度学习下数据不足导致的模型训练不足的问题。数据增强主要通过对原数据做一定修改或者从原数据生成新数据的方法来扩充数据集,增加数据的多样性。数据增强在CV领域应用广泛,比如裁剪图片、旋转图片、对比度调节等方法,但相对于图片,文本是一个离散的字符序列,很多方法不再适用,相对来说文本增强更加困难一些。下面就介绍一些NLP中常用的文本增强方法:
第一种,基于意译的方法
基于意译的方法是通过各种方式生成与原数据释义相近的文本作为增强数据,可以增加数据集的多样性。
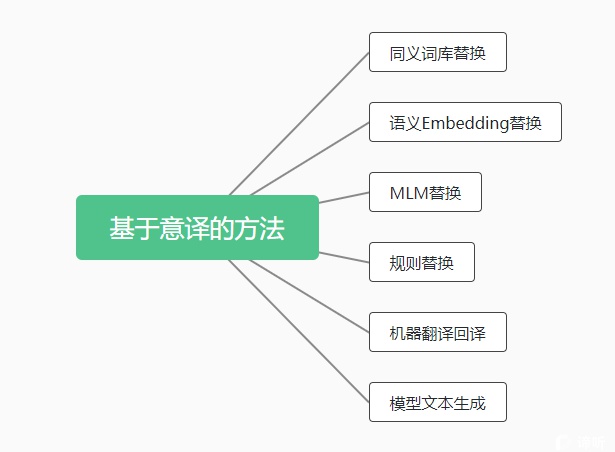
(1)同义词库替换:使用词库中的同近义词替换文本中的词语。
简评:替换词的范围和词性有限;词库无法解决歧义问题;替换太多可能影响语义。
(2)语义Embedding替换:根据词向量选择在向量空间上语义相近的词语或短语进行替换。
简评:替换词的范围更广,但静态词向量同样会面临词的歧义问题;替换多了可能影响语义。
(3)MLM替换:使用预训练语言模型的的MLM任务,替换文本中的某个字词。
简评:利用了上下文,有一定消歧能力,但是mask的长度有限,多数为词级别。
(4)规则替换:使用启发式的规则替换同义字词,如英文中的is not 和 isn’t,或者替换句式。某些场景下,甚至可以通过替换反义词,生成负例样本。
简评:不会改变原语义,但是规则需要人工设定,覆盖范围有限。
(5)机器翻译:主要通过回译的方式生成同义或近义的文本。
简评:能够保证语法和语义正确,但是严重依赖于机器翻译模型的效果,并且使用单一翻译模型的话,还会限制生成数据的多样性。
(6)模型生成:使用Seq2Seq等模型直接生成同义或近义的文本。
简评:可以生成多样性的数据,但是此方法需要大量的训练数据,并且训练的复杂度也比较高,成本较高。
第二种,基于加噪的方法
基于加噪的方法主要通过对原始数据加噪声的方式生成增强数据,可以增加数据集的鲁棒性。
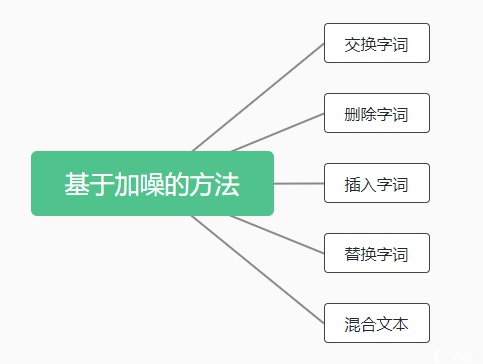
(1)交换字词:随机交换文本中两个字词的位置。
(2)删除字词:随机删除文本中的个别字词。
(3)插入字词:在文本中随机插入其他字词或标点符号,或重复字词。
(4)替换字词:随机替换文本中的个别字词。
(5)混合文本:特定任务下,混合多条数据作为一条数据。
简评:文本加噪的方法非常易于使用,且在一定程度上模仿了人的一些错误写法,可以提升模型的鲁棒性,但是加噪后可能造成句法和语义的扭曲,影响模型效果,而且这些方法对数据多样性的贡献有限。
第三种,其他方法
(1)对比学习
近期对比学习的研究热度空前,对比学习就是在无标签数据上构建正负对比样例来学习文本的隐含模式,对比学习在NLP中也有应用,如SimCSE。对比学习中通过样本自身构建正例的过程就可以近似的认为是一种数据增强,比如SimCSE中一个样本在编码是通过两次dropout得到的不同编码作为正例,这也可以作为一种文本增强手段。
(2)使用大型语言模型如GPT-3
GPT3这种千亿级参数的大模型,性能强大,内部蕴含的知识非常多,具有很大的挖掘潜能。例如,可以人工挑选出模型难以学会的困难样本,让GPT-3去生成更多更丰富的同类困难样本,然后人工审查优化,由此能够以较低人力成本构建出规模更大、更丰富的数据集。
(3)自训练方法
在已标注的小数据集上,先训练一个模型,然后用此模型去对数据进行预标注,再人工审查标注结果,丰富数据集后再训练,再迭代,由此可以花费较少人力得到更多数据。。
文本增强相关的python库推荐:
https://github.com/QData/TextAttack
https://github.com/makcedward/nlpaug
https://github.com/zhanlaoban/eda_nlp_for_Chinese
https://github.com/jasonwei20/eda_nlp
https://github.com/google-research/uda
参考资料
[2110.01852v2] Data Augmentation Approaches in Natural Language Processing: A Survey (arxiv.org)
[2201.05955] WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation (arxiv.org)





关注我们

微信公众号

+86-15708480466